Week 13: Naive Bayes Classifiers#
Laboratory 9
Last updated November 11, 2024
00. Content #
Mathematics
Bayes’ Theorem
Programming Skills
Machine Learning
Embedded Systems
N/A
0. Required Hardware #
N/A
Write your name and email below:
Name:
Email:
1. Introduction to Bayes’ Theorem #
Mathematical Formulation#
Bayes’ Theorem is a fundamental concept in probability theory that describes the relationship between conditional probabilities. Mathematically, it is expressed as:
Where:
\(P(A | B)\) is the probability of event \(A\) occurring given that event \(B\) has occurred.
\(P(B | A)\) is the probability of event \(B\) occurring given that event \(A\) has occurred.
\(P(A)\) and \(P(B)\) are the probabilities of events \(A\) and \(B\) occurring independently.
Bayes’ Theorem allows us to update our beliefs about the probability of an event based on new evidence. It provides a way to reverse conditional probabilities. In other words, if we know \(P(B | A)\), we can find \(P(A | B)\) by considering the overall likelihoods of \(A\) and \(B\).
Imagine you’re trying to determine how likely it is that someone has a disease (\(A\)) after they’ve received a positive test result (\(B\)). Bayes’ Theorem helps you combine the test accuracy with the prevalence of the disease to find the updated probability.
Exercise 1: The Disease Paradox#
Consider a rare disease that affects 1 in 10,000 people. A medical test has the following characteristics:
True Positive Rate: If a person has the disease, the test correctly identifies it 99% of the time.
False Positive Rate: If a person does not have the disease, the test incorrectly indicates they have it 1% of the time.
A randomly selected person from the general population takes the test and receives a positive result. Apply Bayes’ theorem to calculate the probability that this person actually has the disease.
Exercise 2: Changing the False Positive Rate#
For what value of the false positive rate would the probability of having the disease given a positive test result be equal to 50%? In other words, find the value of \(P(T | \overline{D})\) that makes \(P(D | T) = 0.5\). Give your answer as a LaTeX equation, not a python script
2. Naive Bayes Classification#
Introduction to Classifiers#
In machine learning, a classifier is an algorithm that assigns a category or class label to input data based on its features. Classifiers are essential tools for tasks like detecting spam emails, image recognition, and medical diagnosis.
Features and Labels#
Features: The measurable properties or characteristics of the data used for analysis. They are the inputs to the classifier.
Class Labels: The output categories or classes that we aim to predict. They represent the classification outcome.
Examples of Features and Labels#
Classifier Type |
Features |
Class Labels |
|---|---|---|
Spam Email Classifier |
Words in the email, email length, presence of links, sender’s address |
“Spam” and “Not Spam” |
Medical Diagnosis Classifier |
Patient age, blood pressure, cholesterol level, presence of specific symptoms |
“Disease” and “No Disease” (or specific diseases like “Diabetes,” “Hypertension”) |
Image Classifier |
Pixel values, color histograms, shapes, textures |
“Dog,” “Cat,” “Bird,” etc. |
Naive Bayes Classifier#
The Naive Bayes classifier is a simple yet powerful probabilistic classifier based on Bayes’ Theorem. It assumes that the features are independent given the class label—a “naive” assumption that simplifies computation but still often yields effective results.
How It Works#
Given a feature vector \(X = (x_1, x_2, ..., x_n)\) and a class \(C\), the Naive Bayes classifier computes the posterior probability \(P(C | X)\) and assigns \(X\) to the class with the highest posterior probability.
The classifier uses Bayes’ Theorem:
There are several different types of Naive Bayes classifiers. Each assumes a different distribution for the features.
1. Gaussian Naive Bayes#
This is used when the probabilities of the features are continuous and are assumed to follow a Gaussian (normal) distribution. For a feature \(x_i\) given class \(C\), the likelihood is modeled as: $\( P(x_i \mid C) = \frac{1}{\sqrt{2\pi\sigma_C^2}} \exp\left(-\frac{(x_i - \mu_C)^2}{2\sigma_C^2}\right) \)\( where \) \mu_C \( is the mean and \) \sigma_C^2 \( is the variance of the feature in class \)C$.
2. Multinomial Naive Bayes#
This is suited for discrete data, especially when features represent counts (like word frequencies in text classification). It assumes that the features follow a multinomial distribution. For a feature vector \( \mathbf{x} = (x_1, x_2, ..., x_n) \), the likelihood is given by: $\( P(\mathbf{x} \mid C) = P(C) \prod_{i=1}^{n} P(x_i \mid C)^{x_i} \)\( Here, \) P(x_i \mid C) \( is the probability of feature \)x_i\( given class \)C\(, and \) x_i \( represents the count of feature \)i$.
3. Bernoulli Naive Bayes#
This is designed for binary feature vectors, where each feature can either be 0 or 1 (presence or absence). The likelihood for Bernoulli Naive Bayes is: $\( P(\mathbf{x} \mid C) = P(C) \prod_{i=1}^{n} P(x_i \mid C)^{x_i} (1 - P(x_i \mid C))^{(1 - x_i)} \)\( where \)x_i\( is 1 if the feature is present and 0 otherwise, and \)P(x_i \mid C)\( is the probability of feature \)x_i\( being 1 given the class \)C$.
4. Categorical Naive Bayes#
This variant is used when the features are categorical (not ordered). Each feature can take on a finite number of discrete values, and it is modeled using a categorical distribution. For a feature \(x_i\) that can take on one of \(k\) values: $\( P(x_i = v_k \mid C) = P(v_k \mid C) \)\( where \)P(v_k \mid C)\( is the probability that feature \)x_i\( takes the value \)v_k\( given class \)C$.
Naive Bayes Variant |
Best Use Case |
Feature Types |
Example Features |
|---|---|---|---|
Gaussian Naive Bayes |
Features are continuous and assume a normal (Gaussian) distribution |
Continuous |
Exam scores in a calculus class, height of a population |
Multinomial Naive Bayes |
Features represent counts or frequency of occurrences |
Count data, frequency data |
Frequencies of words in text classification |
Bernoulli Naive Bayes |
Features are binary indicators (e.g., presence/absence of a feature) |
Binary |
Presence of a disease in medical diagnosis |
Categorical Naive Bayes |
Features are categorical and do not assume any ordering or continuity |
Categorical/discrete |
Weather (e.g., sunny, cloudy, rainy) |
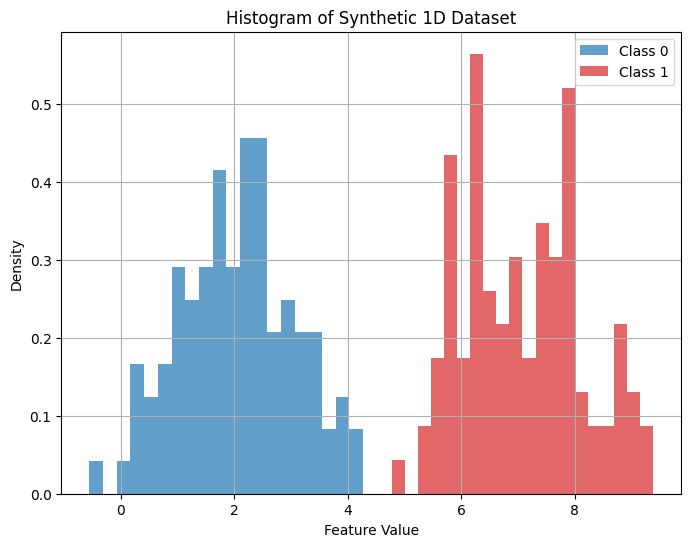
Exercise 3: Gaussian Naive Bayes Illustration#
The following code generates and plots two classes of data points with Gaussian distributions.
Fit the classes to Gaussian distributions and plot the data with the Gaussian curves.
Find the value of \(x\) so that the probability of a data point belonging to each of the two classes is equal. Plot a vertical line at this value. This point is the decision boundary between the two classes.
import numpy as np
import matplotlib.pyplot as plt
# Set random seed for reproducibility
np.random.seed(0)
# Parameters for Class 0
mean0 = 2
std0 = 1 # Standard deviation
# Parameters for Class 1
mean1 = 7
std1 = 1 # Standard deviation
# Number of samples per class
n_samples = 100
# Generate data for Class 0
X0 = np.random.normal(mean0, std0, n_samples)
y0 = np.zeros(n_samples)
# Generate data for Class 1
X1 = np.random.normal(mean1, std1, n_samples)
y1 = np.ones(n_samples)
# Combine the data
X = np.concatenate((X0, X1))
y = np.concatenate((y0, y1))
# Plotting
plt.figure(figsize=(8, 6))
plt.hist(X0, bins=20, alpha=0.7, label='Class 0', color='tab:blue', density=True)
plt.hist(X1, bins=20, alpha=0.7, label='Class 1', color='tab:red', density=True)
plt.xlabel('Feature Value')
plt.ylabel('Density')
plt.title('Histogram of Synthetic 1D Dataset')
plt.legend()
plt.grid(True)
plt.show()
3. A Simple Example #
In this example, we’ll demonstrate Categorical Naive Bayes classification using only one categorical feature: Weather.
Problem Statement#
Suppose we have data about whether children decide to Play outside based on the Weather conditions. The possible weather conditions are:
Sunny
Overcast
Rainy
Our dataset:
Day |
Weather |
Play |
|---|---|---|
1 |
Sunny |
No |
2 |
Sunny |
No |
3 |
Overcast |
Yes |
4 |
Rainy |
Yes |
5 |
Rainy |
Yes |
6 |
Rainy |
No |
7 |
Overcast |
Yes |
8 |
Sunny |
No |
9 |
Sunny |
Yes |
10 |
Rainy |
Yes |
11 |
Sunny |
Yes |
12 |
Overcast |
Yes |
13 |
Overcast |
Yes |
14 |
Rainy |
No |
Predict whether children will Play or Not Play on a Sunny day.
Exercise 4: Calculate the Probabilities#
Calculate the prior probabilities of each class (Play = Yes or No):
Exercise 5: Calculate the Conditional Probabilities#
Calculate the likelihood of each weather condition given the class (e.g. \( P(\text{Weather | Play = Yes})\)).
Exercise 6: Calculate the Posterior Probabilities#
Predict whether children will Play or Not Play on a Sunny day.
Exercise 7: The Multivariate Case#
Write an expression for the posterior probability \( P(C | X) \) in the multivariate case, where \( X = (x_1, x_2, ..., x_n) \) represents multiple features. Express your answer in terms of \(x_i\), assuming that the features are independent given the class label \(C\).
4. Heart disease #
The UCI Machine Learning Repository’s Heart Disease dataset is a popular benchmark for classification tasks in machine learning. It contains medical data from individuals, with the goal of predicting the presence or absence of heart disease based on several attributes like age, sex, cholesterol levels, blood pressure, and others. This dataset is ideal for demonstrating classification algorithms like Naive Bayes because it includes both continuous and categorical features. To use this dataset in Python, you can install the ucimlrepo package, which provides easy access to datasets from the UCI repository. Install the package using the command:
pip install ucimlrepo
After installation, you can load the heart disease dataset as follows:
from ucimlrepo import fetch_ucirepo
heart_disease = fetch_ucirepo(id=45)
# data (as pandas dataframes)
X = heart_disease.data.features
y = heart_disease.data.targets
You can examine the metadata and variables to learn more about the dataset
# metadata
print(heart_disease.metadata)
# variable information
print(heart_disease.variables)
{'uci_id': 45, 'name': 'Heart Disease', 'repository_url': 'https://archive.ics.uci.edu/dataset/45/heart+disease', 'data_url': 'https://archive.ics.uci.edu/static/public/45/data.csv', 'abstract': '4 databases: Cleveland, Hungary, Switzerland, and the VA Long Beach', 'area': 'Health and Medicine', 'tasks': ['Classification'], 'characteristics': ['Multivariate'], 'num_instances': 303, 'num_features': 13, 'feature_types': ['Categorical', 'Integer', 'Real'], 'demographics': ['Age', 'Sex'], 'target_col': ['num'], 'index_col': None, 'has_missing_values': 'yes', 'missing_values_symbol': 'NaN', 'year_of_dataset_creation': 1989, 'last_updated': 'Fri Nov 03 2023', 'dataset_doi': '10.24432/C52P4X', 'creators': ['Andras Janosi', 'William Steinbrunn', 'Matthias Pfisterer', 'Robert Detrano'], 'intro_paper': {'ID': 231, 'type': 'NATIVE', 'title': 'International application of a new probability algorithm for the diagnosis of coronary artery disease.', 'authors': 'R. Detrano, A. Jánosi, W. Steinbrunn, M. Pfisterer, J. Schmid, S. Sandhu, K. Guppy, S. Lee, V. Froelicher', 'venue': 'American Journal of Cardiology', 'year': 1989, 'journal': None, 'DOI': None, 'URL': 'https://www.semanticscholar.org/paper/a7d714f8f87bfc41351eb5ae1e5472f0ebbe0574', 'sha': None, 'corpus': None, 'arxiv': None, 'mag': None, 'acl': None, 'pmid': '2756873', 'pmcid': None}, 'additional_info': {'summary': 'This database contains 76 attributes, but all published experiments refer to using a subset of 14 of them. In particular, the Cleveland database is the only one that has been used by ML researchers to date. The "goal" field refers to the presence of heart disease in the patient. It is integer valued from 0 (no presence) to 4. Experiments with the Cleveland database have concentrated on simply attempting to distinguish presence (values 1,2,3,4) from absence (value 0). \n \nThe names and social security numbers of the patients were recently removed from the database, replaced with dummy values.\n\nOne file has been "processed", that one containing the Cleveland database. All four unprocessed files also exist in this directory.\n\nTo see Test Costs (donated by Peter Turney), please see the folder "Costs" ', 'purpose': None, 'funded_by': None, 'instances_represent': None, 'recommended_data_splits': None, 'sensitive_data': None, 'preprocessing_description': None, 'variable_info': 'Only 14 attributes used:\r\n 1. #3 (age) \r\n 2. #4 (sex) \r\n 3. #9 (cp) \r\n 4. #10 (trestbps) \r\n 5. #12 (chol) \r\n 6. #16 (fbs) \r\n 7. #19 (restecg) \r\n 8. #32 (thalach) \r\n 9. #38 (exang) \r\n 10. #40 (oldpeak) \r\n 11. #41 (slope) \r\n 12. #44 (ca) \r\n 13. #51 (thal) \r\n 14. #58 (num) (the predicted attribute)\r\n\r\nComplete attribute documentation:\r\n 1 id: patient identification number\r\n 2 ccf: social security number (I replaced this with a dummy value of 0)\r\n 3 age: age in years\r\n 4 sex: sex (1 = male; 0 = female)\r\n 5 painloc: chest pain location (1 = substernal; 0 = otherwise)\r\n 6 painexer (1 = provoked by exertion; 0 = otherwise)\r\n 7 relrest (1 = relieved after rest; 0 = otherwise)\r\n 8 pncaden (sum of 5, 6, and 7)\r\n 9 cp: chest pain type\r\n -- Value 1: typical angina\r\n -- Value 2: atypical angina\r\n -- Value 3: non-anginal pain\r\n -- Value 4: asymptomatic\r\n 10 trestbps: resting blood pressure (in mm Hg on admission to the hospital)\r\n 11 htn\r\n 12 chol: serum cholestoral in mg/dl\r\n 13 smoke: I believe this is 1 = yes; 0 = no (is or is not a smoker)\r\n 14 cigs (cigarettes per day)\r\n 15 years (number of years as a smoker)\r\n 16 fbs: (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)\r\n 17 dm (1 = history of diabetes; 0 = no such history)\r\n 18 famhist: family history of coronary artery disease (1 = yes; 0 = no)\r\n 19 restecg: resting electrocardiographic results\r\n -- Value 0: normal\r\n -- Value 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV)\r\n -- Value 2: showing probable or definite left ventricular hypertrophy by Estes\' criteria\r\n 20 ekgmo (month of exercise ECG reading)\r\n 21 ekgday(day of exercise ECG reading)\r\n 22 ekgyr (year of exercise ECG reading)\r\n 23 dig (digitalis used furing exercise ECG: 1 = yes; 0 = no)\r\n 24 prop (Beta blocker used during exercise ECG: 1 = yes; 0 = no)\r\n 25 nitr (nitrates used during exercise ECG: 1 = yes; 0 = no)\r\n 26 pro (calcium channel blocker used during exercise ECG: 1 = yes; 0 = no)\r\n 27 diuretic (diuretic used used during exercise ECG: 1 = yes; 0 = no)\r\n 28 proto: exercise protocol\r\n 1 = Bruce \r\n 2 = Kottus\r\n 3 = McHenry\r\n 4 = fast Balke\r\n 5 = Balke\r\n 6 = Noughton \r\n 7 = bike 150 kpa min/min (Not sure if "kpa min/min" is what was written!)\r\n 8 = bike 125 kpa min/min \r\n 9 = bike 100 kpa min/min\r\n 10 = bike 75 kpa min/min\r\n 11 = bike 50 kpa min/min\r\n 12 = arm ergometer\r\n 29 thaldur: duration of exercise test in minutes\r\n 30 thaltime: time when ST measure depression was noted\r\n 31 met: mets achieved\r\n 32 thalach: maximum heart rate achieved\r\n 33 thalrest: resting heart rate\r\n 34 tpeakbps: peak exercise blood pressure (first of 2 parts)\r\n 35 tpeakbpd: peak exercise blood pressure (second of 2 parts)\r\n 36 dummy\r\n 37 trestbpd: resting blood pressure\r\n 38 exang: exercise induced angina (1 = yes; 0 = no)\r\n 39 xhypo: (1 = yes; 0 = no)\r\n 40 oldpeak = ST depression induced by exercise relative to rest\r\n 41 slope: the slope of the peak exercise ST segment\r\n -- Value 1: upsloping\r\n -- Value 2: flat\r\n -- Value 3: downsloping\r\n 42 rldv5: height at rest\r\n 43 rldv5e: height at peak exercise\r\n 44 ca: number of major vessels (0-3) colored by flourosopy\r\n 45 restckm: irrelevant\r\n 46 exerckm: irrelevant\r\n 47 restef: rest raidonuclid (sp?) ejection fraction\r\n 48 restwm: rest wall (sp?) motion abnormality\r\n 0 = none\r\n 1 = mild or moderate\r\n 2 = moderate or severe\r\n 3 = akinesis or dyskmem (sp?)\r\n 49 exeref: exercise radinalid (sp?) ejection fraction\r\n 50 exerwm: exercise wall (sp?) motion \r\n 51 thal: 3 = normal; 6 = fixed defect; 7 = reversable defect\r\n 52 thalsev: not used\r\n 53 thalpul: not used\r\n 54 earlobe: not used\r\n 55 cmo: month of cardiac cath (sp?) (perhaps "call")\r\n 56 cday: day of cardiac cath (sp?)\r\n 57 cyr: year of cardiac cath (sp?)\r\n 58 num: diagnosis of heart disease (angiographic disease status)\r\n -- Value 0: < 50% diameter narrowing\r\n -- Value 1: > 50% diameter narrowing\r\n (in any major vessel: attributes 59 through 68 are vessels)\r\n 59 lmt\r\n 60 ladprox\r\n 61 laddist\r\n 62 diag\r\n 63 cxmain\r\n 64 ramus\r\n 65 om1\r\n 66 om2\r\n 67 rcaprox\r\n 68 rcadist\r\n 69 lvx1: not used\r\n 70 lvx2: not used\r\n 71 lvx3: not used\r\n 72 lvx4: not used\r\n 73 lvf: not used\r\n 74 cathef: not used\r\n 75 junk: not used\r\n 76 name: last name of patient (I replaced this with the dummy string "name")', 'citation': None}}
name role type demographic \
0 age Feature Integer Age
1 sex Feature Categorical Sex
2 cp Feature Categorical None
3 trestbps Feature Integer None
4 chol Feature Integer None
5 fbs Feature Categorical None
6 restecg Feature Categorical None
7 thalach Feature Integer None
8 exang Feature Categorical None
9 oldpeak Feature Integer None
10 slope Feature Categorical None
11 ca Feature Integer None
12 thal Feature Categorical None
13 num Target Integer None
description units missing_values
0 None years no
1 None None no
2 None None no
3 resting blood pressure (on admission to the ho... mm Hg no
4 serum cholestoral mg/dl no
5 fasting blood sugar > 120 mg/dl None no
6 None None no
7 maximum heart rate achieved None no
8 exercise induced angina None no
9 ST depression induced by exercise relative to ... None no
10 None None no
11 number of major vessels (0-3) colored by flour... None yes
12 None None yes
13 diagnosis of heart disease None no
We will simplify the problem by converting the target variable from its original range of 0 to 4 into a binary classification: 0 for no heart disease and 1 for the presence of heart disease.
Because we will be fitting the data to a gaussian model, we will discard binary features, such as exercise-induced angina (exang), and multinomial features, such as chest pain type (cp).
y = y.applymap(lambda x: 0 if x == 0 else 1)
X = X[['age', 'trestbps', 'chol', 'thalach', 'oldpeak']]
C:\Users\chris\AppData\Local\Temp\ipykernel_16756\3801226080.py:1: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
y = y.applymap(lambda x: 0 if x == 0 else 1)
Exercise 8: Building Intuition#
Choose two features, and make a contour plot of the likelihood of heart disease as a function of these features in matplotlib.
Hint: The easiest way to do this is probably to make a scatter plot where the colors of the points correspond to the likelihood of having heart disease`.
Training a Gaussian Naive Bayes Classifier#
In this section, we will train a Gaussian Naive Bayes classifier using scikit-learn to predict the presence and severity of heart disease based on patient data.
import numpy as np
# Assuming age, trestbps, chol, thalach, oldpeak, ca, and y are already defined numpy arrays
# Stack the feature arrays into a single feature matrix
# X = np.column_stack((age, trestbps, chol, thalach, oldpeak, ca))
X = X.to_numpy()
# Check the shape of X and y
print("Shape of X:", X.shape)
print("Shape of y:", y.shape)
Shape of X: (303, 5)
Shape of y: (303, 1)
Here, we have combined all the feature arrays into a two-dimensional feature matrix X, where each row represents a patient, and each column represents a feature.
Splitting the Data into Training and Testing Sets#
We will split the data into training and testing sets to evaluate the performance of our classifier on unseen data.
from sklearn.model_selection import train_test_split
# Split the data: 80% training and 20% testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Check the shapes of the splits
print("Training set shape:", X_train.shape)
print("Testing set shape:", X_test.shape)
Training set shape: (242, 5)
Testing set shape: (61, 5)
We use train_test_split from scikit-learn to randomly split the dataset while preserving the distribution of the target variable.
Training the Classifier#
Now, we will instantiate the Gaussian Naive Bayes classifier and train it on the training data.
from sklearn.naive_bayes import GaussianNB
# Instantiate the classifier
gnb = GaussianNB()
# Train the classifier
gnb.fit(X_train, y_train)
c:\Users\chris\miniconda3\envs\qutip-env\Lib\site-packages\sklearn\utils\validation.py:1339: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
GaussianNB()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GaussianNB()
Evaluating the Classifier#
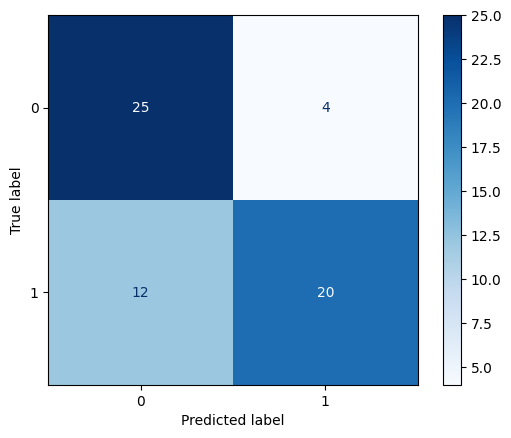
We will evaluate the classifier’s performance using a confusion matrix, which provides a summary of prediction results.
The confusion matrix provides the following information:
True Positives (TP): Correctly predicted positive observations.
True Negatives (TN): Correctly predicted negative observations.
False Positives (FP): Incorrectly predicted positive observations.
False Negatives (FN): Incorrectly predicted negative observations.
By analyzing the confusion matrix, we can understand where the classifier is making mistakes and how it can be improved.
from sklearn.metrics import ConfusionMatrixDisplay, accuracy_score
import matplotlib.pyplot as plt
# Make predictions on the test set
y_pred = gnb.predict(X_test)
# Display the confusion matrix
disp = ConfusionMatrixDisplay.from_predictions(y_test, y_pred, cmap='Blues')
Calculating Accuracy#
We can also evaluate the model’s accuracy. Accuracy measures how often the classifier’s predictions are correct, and it’s calculated using the following formula:
In this case:
y_testcontains the true labels for the test dataset. These are the correct answers, the ground truth.y_predcontains the predicted labels, which are the guesses made by the classifier for the test data.
The function accuracy_score(y_test, y_pred) compares the predicted labels (y_pred) with the actual labels (y_test) to count how many predictions are correct. It then divides the number of correct predictions by the total number of predictions to calculate the accuracy.
For example, if we had 100 test samples and the classifier predicted 90 of them correctly, the accuracy would be:
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy of the classifier:", accuracy)
Accuracy of the classifier: 0.7377049180327869
Exercise 9: Evaluating the model #
From the confusion matrix, are the true positives, true negatives, false positives, and false negatives for this model?
Which is a more meaningful way to evaluate the model’s performance: accuracy or the confusion matrix? Why?
Is the classifier a good model? Why or why not?
Visualizing Decision Boundaries#
To visualize the decision boundaries, we can plot the classifier’s predictions over a grid of feature values. Since we cannot plot in more than two dimensions, we’ll select pairs of features.
The following code takes two features from the matrix of features and trains a model using those features alone. It then plots the decision boundaries for the model.
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np
# Feature names for labeling
feature_names = ['age', 'trestbps']
# Define colormap for 5 classes
cmap_light = ListedColormap(np.flip(['#FFAAAA', '#AAFFAA', '#AAAAFF', '#FFAAFF', '#AAFFFF']))
cmap_bold = np.flip(['tab:red', 'tab:green', 'tab:blue', 'tab:purple', 'tab:cyan'])
# Select two features to plot
i, j = 0, 1
X_pair = X_train[:, [i, j]]
y_pair = y_train
# Create meshgrid
x_min, x_max = X_pair[:, 0].min() - 1, X_pair[:, 0].max() + 1
y_min, y_max = X_pair[:, 1].min() - 1, X_pair[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200),
np.linspace(y_min, y_max, 200))
# Fit classifier on the pair of features
gnb = GaussianNB()
gnb.fit(X_pair, y_pair)
Z = gnb.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plotting decision boundary
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.4, cmap=cmap_light)
# Plotting the actual data points
scatter = plt.scatter(X_pair[:, 0], X_pair[:, 1], c=y_pair.values, s=20, cmap=ListedColormap(cmap_bold), edgecolor='k')
plt.xlabel(f"{feature_names[i]}")
plt.ylabel(f"{feature_names[j]}")
plt.title(f"Decision Boundary using features '{feature_names[i]}' and '{feature_names[j]}'")
# Custom legend handling
legend1 = plt.legend(*scatter.legend_elements(), title="Classes")
plt.gca().add_artist(legend1)
c:\Users\chris\miniconda3\envs\qutip-env\Lib\site-packages\sklearn\utils\validation.py:1339: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
<matplotlib.legend.Legend at 0x1678d3fa790>
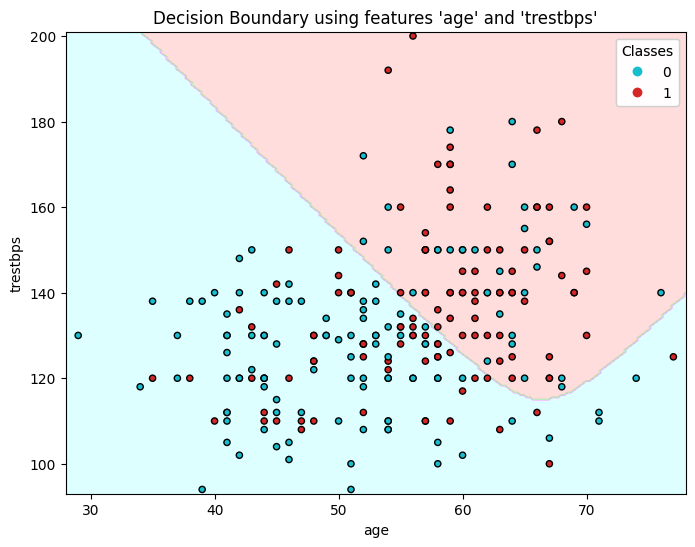
Exercise 10: Plotting decision boundaries #
Plot the decision boundaries for different pairs of features.
Which pairs of features seem to be the best predictors of heart disease? Which pairs of features seem to be poor predictors of heart disease?